Serverless teams move well when they agree on ownership, testing, visibility, and security before the function count grows. If I had to boil this down, I’d focus on five things: clear owners, versioned contracts, code and IaC in one workflow, shared alerts and runbooks, and least-privilege access checked in every PR.
In plain English: serverless gets messy when many small functions, queues, APIs, and roles change at once. That’s why I need one team playbook for how functions are named, who owns production issues, how preview environments are created, what gets tested, and how alerts are routed. The article shows that teams cut incident triage from hours to minutes with shared logs and tracing, and some orgs saw 55% less alert fatigue after sending richer alerts with trace links and runbook URLs.
Here’s the short version:
Set rules early: define function boundaries, event schemas, naming patterns, and production owners
Ship code and infrastructure together: treat handlers, IAM, triggers, and env settings as one release unit
Test in layers: unit tests, cloud-based integration tests, and deploy checks for IAM and config drift
Make failures easy to trace: standardize JSON logs, trace IDs, p95/p99 latency, queue depth, and DLQ metrics
Route alerts by severity: P1 to paging, P2 to chat, P3 to email, with links to logs, traces, and runbooks
Build security into daily work: one IAM role per function, secrets in Secrets Manager or Parameter Store, and PR scans for leaked credentials and weak policies
Use platform guardrails: SCPs, permission boundaries, policy-as-code, and approved templates keep teams aligned as they grow
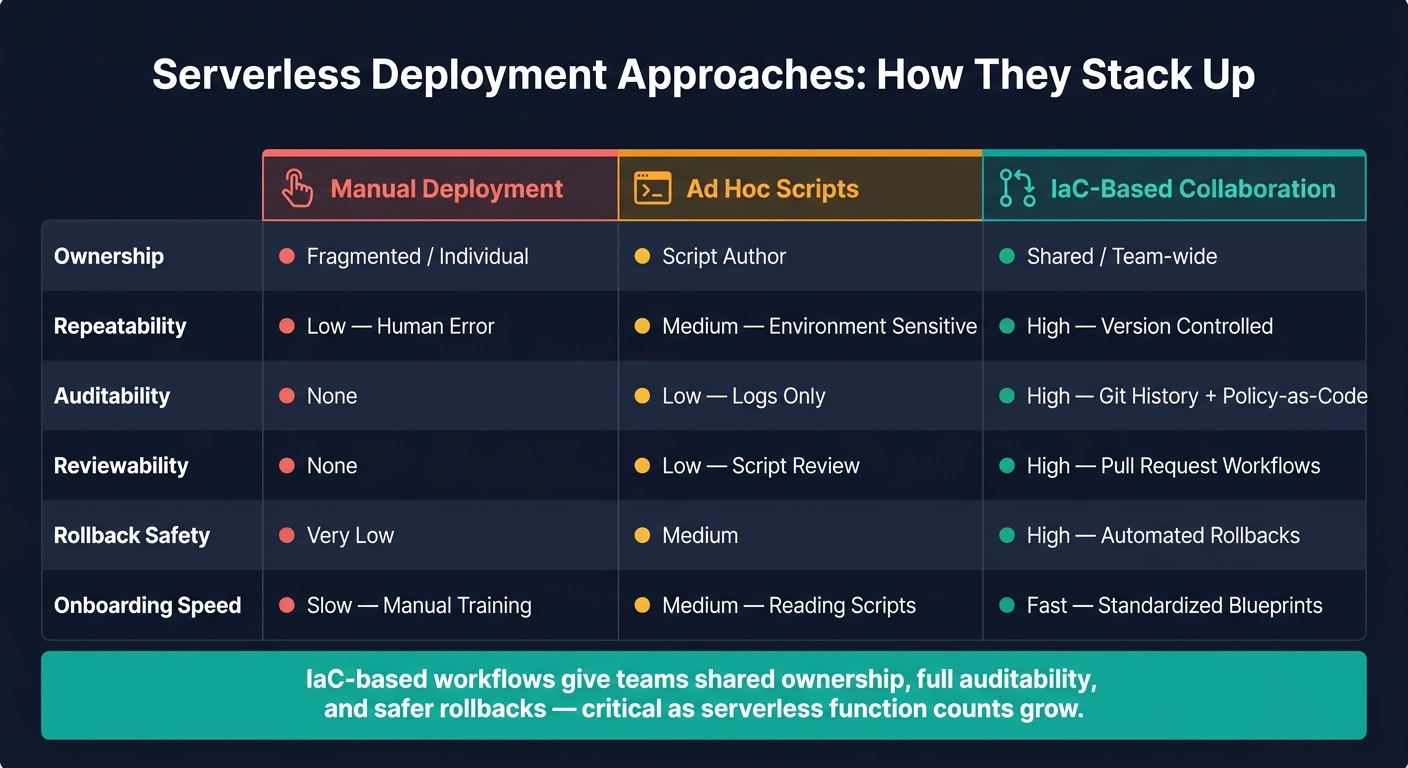
Quick comparison: the article also makes one point very clear - manual deploys and one-off scripts break down fast when several teams have to work in the same system.
Approach
Ownership
Review
Rollback
Audit trail
Manual deployment
One person
Little to none
Weak
Weak
Ad hoc scripts
Script owner
Limited
Mixed
Partial
IaC-based workflow
Shared team model
PR-based
Safer
Git-based
That’s the core idea: if I want serverless delivery to stay fast without losing control, I need shared workflow rules, shared production ownership, and checks built into the same path teams already use to ship code.
AWS re:Invent 2024 - Best practices for serverless developers (SVS401)
sbb-itb-18d4e20
Set team workflow standards before scaling delivery
Once ownership is clear, lock in the team’s day-to-day workflow.
Without a shared way of working, serverless delivery turns into a coordination mess fast. People deploy functions in different ways, ownership gets blurry, and incident response drags because no one agrees on who owns what. The answer is shared process before sprawl kicks in, not a bigger pile of tools.
Define function boundaries, event contracts, and ownership
Document each function’s trigger, input, output, and production owner. That makes handoffs, code reviews, and incident response much easier to handle.
If teams share event buses or message queues, shared schemas need versioned contracts and a named change owner. That helps prevent one service from breaking another.
Keep API contracts - OpenAPI or AsyncAPI specs - in the same repo as the function code. Then fail the build if the code and contract drift apart.
Ownership should be just as clear. The team that ships the function also owns its production health. Assign domain owners to specific business areas so that responsibility stays clear as the team grows.
Once ownership is set, the next step is to standardize how code moves through the repo and pull request flow.
Standardize repositories, naming, and pull request rules
Repo structure and naming rules shape both onboarding and daily work more than most teams expect.
Use a clear layout like:
services/
libs/
tests/
For naming, stick to one pattern across environments, such as ${service}-${stage}-${resource}. It cuts down on environment mix-ups and makes ownership easy to spot at a glance.
Keep branching simple too: use feature branches for development, a protected main for integration, and tagged releases for production. If something goes wrong, roll back by reverting the release commit.
One of the highest-impact habits here is spinning up ephemeral preview environments for every pull request. A stack like preview-pr-128 gives reviewers a live environment to test, not just code to skim. When the PR closes, tear that environment down automatically so you don’t leave orphaned resources running or rack up surprise costs.
"A bonus with Serverless is that you can spin up new environments at zero cost... a team can have dozens of ephemeral stages such as: prod, staging, dev, feature-x, feature-y, pr-128, etc." - Frank Wang
For shared modules, require at least one reviewer from the owning team.
Comparison table: manual deployment vs. ad hoc scripts vs. IaC-based collaboration
Most teams don’t begin with infrastructure as code. They start with manual deployments, then move to scripts, and only later run into the same problem: neither method works well once a team has to move together. Here’s how the three approaches stack up for collaboration:
These rules work best when code and infrastructure change together.
Use infrastructure as code and shared testing to make changes safer
Serverless Deployment Approaches: Manual vs. Scripts vs. IaC Collaboration
Once ownership and PR rules are in place, put code, IaC, and tests on the same release path. Treat code, permissions, triggers, and environment variables as one release unit, because code by itself is not production.
"The safest serverless pipelines treat infrastructure and code as one versioned release unit. That does not mean every deploy is massive. It means every deploy is reproducible." - Software Patterns Lexicon
Keep infrastructure and function code in the same workflow
Keep IaC files like serverless.yml, SAM, or CDK right next to your Lambda handlers. Run them through the same PR process and pipeline so infra changes ship with the code they touch. That way, the artifact, IAM roles, event sources, and environment variables all move together.
IaC changes need peer review too, not just app code. Tools like cdk-nag and cfn-lint can scan templates for security issues and config mistakes before anything hits a live environment. In a 2023 case study of Netflix's serverless orchestration layer, Fargo, a mono-repo with CODEOWNERS files that required cross-team reviews grew module reuse from 12 to 48 services in six months, cut pipeline latency by 22%, and reduced duplicate code by 35%.
With the release path set, testing becomes the next checkpoint.
Build a testing stack for code, integrations, and deployments
Use three layers of testing:
Unit tests for function logic
Integration tests for managed services in short-lived cloud environments
Pre-deploy checks for IAM and configuration drift
"Test at the boundary, not through it. Validate what crosses the edge without requiring the entire downstream system." - AWS Prescriptive Guidance
For async flows, add a light async test harness that watches events, database writes, or log streams. Tag each run with a unique correlation ID so tests don't collide with each other.
Create shared visibility, alerting, and incident response practices
After deployment, teamwork depends on shared visibility. Once changes ship safely, teams need one common way to spot failures, assign ownership, and respond fast. And because requests often pass through many services, everyone needs the same view of what’s happening.
Standardize logs, metrics, traces, and dashboards
Teams should standardize structured JSON logs with consistent fields such as timestamp, level, traceId, requestId, functionName, version, and durationMs.
They should also track:
p95 and p99 latency
error and success ratios
cold-start frequency
throttles
concurrent executions
For async workflows, dashboards should also show queue depth, stream lag, iterator age, and dead-letter queue error counts.
Carry trace context through every event and every async hop. A function can look fine on its own while the actual delay or failure comes from a downstream API, database, or queue. Structured logging and distributed tracing can cut debugging time for critical incidents from hours to minutes.
Assign alert ownership and escalation paths
Visibility only works when every alert has an owner and a clear next step. Alerts do their job only when ownership is obvious. Domain teams should own their own service alerts, while platform teams support shared monitoring and cross-account visibility.
A simple routing model helps:
Route P1 outages to paging tools
Send P2 issues to team chat channels
Send P3 informational alerts to email
Enriched alerts should include correlation IDs, trace links, and runbook URLs so on-call teams can move faster.
Alert on ratios instead of raw spikes. For example, Errors / Invocations > 0.03 tells you more than a count of isolated errors. Runbooks should also define escalation thresholds, such as queue age over 900 seconds or dependency error rate above 5%. Routing enriched alerts with trace links and log excerpts to on-call channels reduced alert fatigue by 55% across 70 organizations.
Responsibility table for observability and incident readiness
Use this split to keep instrumentation, alerting, and response from drifting across teams.
Task
Developers
Platform/Ops
Reliability (SRE)
Security
Instrumentation
Add structured logs and propagate trace IDs in function code
Provide standardized SDKs and observability collectors
Define service-level signals and review instrumentation quality
Define sensitive data redaction rules for logs
Dashboarding
Build domain-specific views for business logic and latency
Maintain centralized cross-account dashboards
Keep system-wide health views current
Monitor for unauthorized access patterns
Alert Tuning
Set thresholds for function-level errors and timeouts
Monitor platform-wide limits such as concurrency and throttling
Tune alerts to reduce noise
Set alerts for IAM permission changes
Incident Response
Respond to logic failures and poison messages
Manage pausing triggers and scaling limits
Run post-incident reviews and trace root causes
Contain blast radius during credential leaks or suspicious data flows
Post-Incident
Share undocumented quirks and update domain docs
Add guardrails and update platform templates
Turn incident lessons into follow-up actions
Review data flow and permission boundaries
End every incident review with one new guardrail: a config check, alert threshold, or runbook update.
Build security, governance, and enablement into daily collaboration
Security in serverless setups works best when it becomes part of the team’s daily routine, not a last-minute check. Functions are small, ship fast, and often pile up over time. That means one misconfigured IAM role or one exposed secret can make a bad situation much worse. The fix is simple in principle: put checks inside the same PR and deployment flow teams already use. Security review should happen in every pull request, not as a separate gate.
Review permissions, secrets, and data flows as part of every change
Each Lambda function should have its own IAM role, scoped to the exact resource ARNs and actions it needs, instead of shared roles or broad access. A good starting point is a sandbox with the bare minimum, then tightening roles to exact ARNs instead of wildcards before anything goes to production.
Secrets need the same level of care. Don’t keep sensitive data in environment variables. Use AWS Secrets Manager or SSM Parameter Store instead, and cache secret reads so you cut repeated calls and avoid extra latency.
PRs are where teams can catch permission drift and exposed credentials before they turn into production issues. Adding tools like Bandit, Safety, and detect-secrets to the PR workflow helps flag problems early. Teams should also review event sources and data-flow assumptions as part of each change, rather than waiting for an audit after deployment.
Once those checks exist at the change level, the next step is to bake them into platform rules so people don’t have to spot every issue by hand.
Use platform guardrails, templates, and training to reduce team friction
Governance tends to work better when the platform handles the rules by default. In plain terms, guardrails turn security standards into shared team habits.
Platform teams can use Service Control Policies (SCPs) and Permission Boundaries to limit what any developer is able to grant. That helps stop things like accidental public endpoints or IAM roles that are too open. You can pair that with policy-as-code tools like Checkov to enforce hard rules in CI/CD, such as blocking public S3 buckets or wildcard IAM actions.
Reusable IaC templates and approved CI/CD workflows also help keep secure patterns consistent across teams. A short internal training session now and then can keep people up to date without turning security review into a traffic jam.
How service partners can support team enablement
If the internal platform team is stretched thin, Optiblack can support team enablement through Product Accelerator, Data Infrastructure, and AI Initiatives.
Conclusion: The collaboration habits that make serverless teams effective
Serverless teams scale when collaboration is standardized, not improvised. The teams that do this well usually start early. They keep infrastructure and function code in the same workflow, and they treat security and observability like part of the daily job, not side tasks.
The point isn't the tooling by itself. It's the shared workflow behind it. That's what makes delivery repeatable and helps serverless teamwork hold up as the team grows.
"You build it, you run it."
That lines up with the "you build it, you run it" model: the team that ships a function also owns its runtime health. When developers own production health, speed doesn't come at the cost of reliability.
Standardized workflows, IaC, observability, least-privilege access, and platform guardrails make serverless delivery faster and safer.
FAQs
How do we assign serverless ownership clearly?
Assign one accountable team to the full service lifecycle: design, development, deployment, operations, and security. That team should own the service end to end, not just one slice of it.
Set up teams around business domains or capabilities, with clear control over their service repositories and service boundaries. In plain terms, each team should know: this is ours, and we’re responsible for how it works in production.
Back that up with a knowledge-ownership charter, named stewards, on-call rotations, runbooks, and service-level objectives (SLOs). Those pieces make ownership concrete. They also connect service performance and incident response directly to the team that runs the service.
What should we test before each serverless deploy?
Before each serverless deploy, use a layered testing strategy.
Unit tests on every commit for core business logic, input validation, and data transformation
Integration tests before merging or deploying to check service interactions, IAM permissions, and event structures
End-to-end API and performance checks to catch orchestration issues or configuration drift, including cold starts and response times
How can we reduce alert noise in serverless systems?
Focus alerts on business impact first, especially user-facing failures and problems in critical workflows, rather than on infrastructure symptoms alone. That means watching for what users and the business actually feel, not just CPU spikes or memory pressure.
It also helps to unify logs, metrics, and traces in one consistent format, such as JSON. When telemetry lives in the same shape, teams spend less time stitching together scattered signals and more time figuring out what broke.
To cut down on noise, use automated anomaly detection to sort routine chatter from issues that need attention. Then group alerts by business impact so one incident doesn’t turn into a pile of disconnected notifications. Add bulkheads and concurrency controls as well, which can help stop workload spikes from snowballing into cascading alerts.
Comprehensive guide to self-hosting PostHog on AWS EC2 using Docker Compose, covering setup, configuration, and troubleshooting. Summary: This guide...
Explore the differences between sentiment analysis and emotion recognition, their applications, and how they shape user experience in digital...
Vishal Rewari
Aug 6, 2025
Get notified on new marketing insights
Be the first to know about new B2B SaaS Marketing insights to build or refine your marketing function with the tools and knowledge of today’s industry.